




What's the COCO format?
COCO is a large image dataset designed for object detection, segmentation, person keypoints detection, stuff segmentation, and caption generation. It stores its annotations in the JSON format describing object classes, bounding boxes, and bitmasks.
for storing and using the tools developed for COCO we have to create the dataset like like COCO we can either convert the one which we have to COCO format or we can create one to ourselves
Structure of COCO
{
"info": {
"year": "2021",
"version": "1.0",
"description": "Exported from FiftyOne",
"contributor": "Voxel51",
"url": "https://fiftyone.ai",
"date_created": "2021-01-19T09:48:27"
},
"licenses": [
{
"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/",
"id": 1,
"name": "Attribution-NonCommercial-ShareAlike License"
},
...
],
"categories": [
...
{
"id": 2,
"name": "cat",
"supercategory": "animal"
},
...
],
"images": [
{
"id": 0,
"license": 1,
"file_name": "<filename0>.<ext>",
"height": 480,
"width": 640,
"date_captured": null
},
...
],
"annotations": [
{
"id": 0,
"image_id": 0,
"category_id": 2,
"bbox": [260, 177, 231, 199],
"segmentation": [...],
"area": 45969,
"iscrowd": 0
},
...
]
}
info: this part of the structure gives information about the dataset, version, time, date created, author, etc
licenses: this part gives information about the licenses which we have for our dataset
category: it gives the id for annotations and objects detected along with the name also we can determine subcategories in it
images: it stores images, file names, height width, time is taken, etc
annotations: for the id's we have for images it contains bounding box, segmentation coordinates area
here bounding box is the x1,y1,x2,y2 coordinates of the object detected while the segmentation is the object outline
iscrowd it's the binary parameter that tells if there are multiple objects on the scale we can't really segment each one of them we can convert them into one large box and indicate that with iscrowd parameter
Loading and visualizing COCO format dataset
for this purpose we are gonna use COCO 2017 dataset
 there are prebuilt functions for doing operations on the COCO format
there are prebuilt functions for doing operations on the COCO format
we are gonna use pycocotools library for doing operations on the coco datset
Importing libraries which we need
!pip install pycocotools
import pandas as pd
import os
from pycocotools.coco import COCO
import skimage.io as io
import matplotlib.pyplot as plt
from pathlib import Path
Reading the dataset
dataDir=Path('../input/coco-2017-dataset/coco2017/val2017')
annFile = Path('../input/coco-2017-dataset/coco2017/annotations/person_keypoints_val2017.json')
coco = COCO(annFile)
imgIds = coco.getImgIds()
imgs = coco.loadImgs(imgIds[-3:])
here we are using COCO for reading the annotations I've read validation data annotations
we can get info of our dataset using coco.info() method
coco returns the dictionary of the dataset
here we can get id's of images with coco.getImgIds() function
after getting image id's we have to load those images for loading the images we can use coco.loadImgs()
Visualizing our images
imgs = coco.loadImgs(imgIds[-3:])
_,axs = plt.subplots(len(imgs),2,figsize=(10,5 * len(imgs)))
for img, ax in zip(imgs, axs):
I = io.imread(dataDir/img['file_name'])
annIds = coco.getAnnIds(imgIds=[img['id']])
anns = coco.loadAnns(annIds)
ax[0].imshow(I)
ax[1].imshow(I)
plt.sca(ax[1])
coco.showAnns(anns, draw_bbox=False)
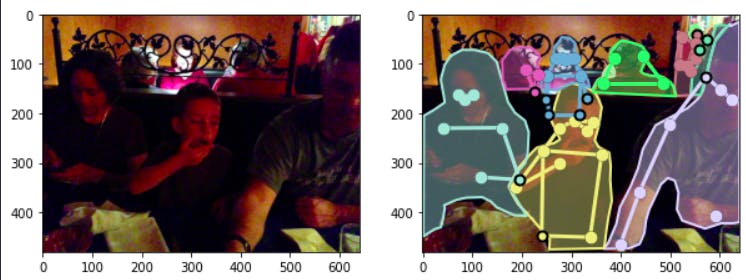 for visualizing the dataset we are using matplotlib here for illustration we are gonna use 3 images
for visualizing the dataset we are using matplotlib here for illustration we are gonna use 3 images
first we display our base image we can get the image_filename from our coco loaded dataset using img['file_name'] (note that we have loaded images with coco.loadImgs() by passing ids of images )
for loading the annotations we have to get annotation id's for getting them we are using getAnnIds() method of coco dictionary
after getting id's we are loading them with coco.loadAnns(annIds) for plotting those id's on the images we have to change the axis of images we are using plt.sca() method this method selects the current axis for editing
and finally we are using coco.showAnns() method for drawing the annotations here we can choose if we want to draw the bounded boxes with draw_bbox parameter.
 we will discuss how to create the COCO dataset with csv files in my another post :)
we will discuss how to create the COCO dataset with csv files in my another post :)
Link for notebook
kaggle.com/somesh88/coco-dataset-representa..
thanks for reading my blog :) follow for more say hi to me in comments it gives me encouragement for writing more blogs :) have a good day :)